Create a virtual environment and activate it (python -m venv venv &&source venv/bin/activate)
Run poetry install to install the packages
If you are a dev and have a data/ folder with you, skip this step.
Run training.py (for the first time/to update the model). This takes care of basically everything.
Install Ollama (https://ollama.com/) and download the models ollama pull llama3
Run ./start_local.sh to start all the services, and navigate to http://localhost:8501 to access the Streamlit frontend.
WAIT for a few minutes for the services to start. The terminal should show "sending first query to avoid cold start". Things will only work after this message.
Do not open the uvicorn server directly, as it will not work.
To stop the services, run ./stop_local.sh from a different terminal.
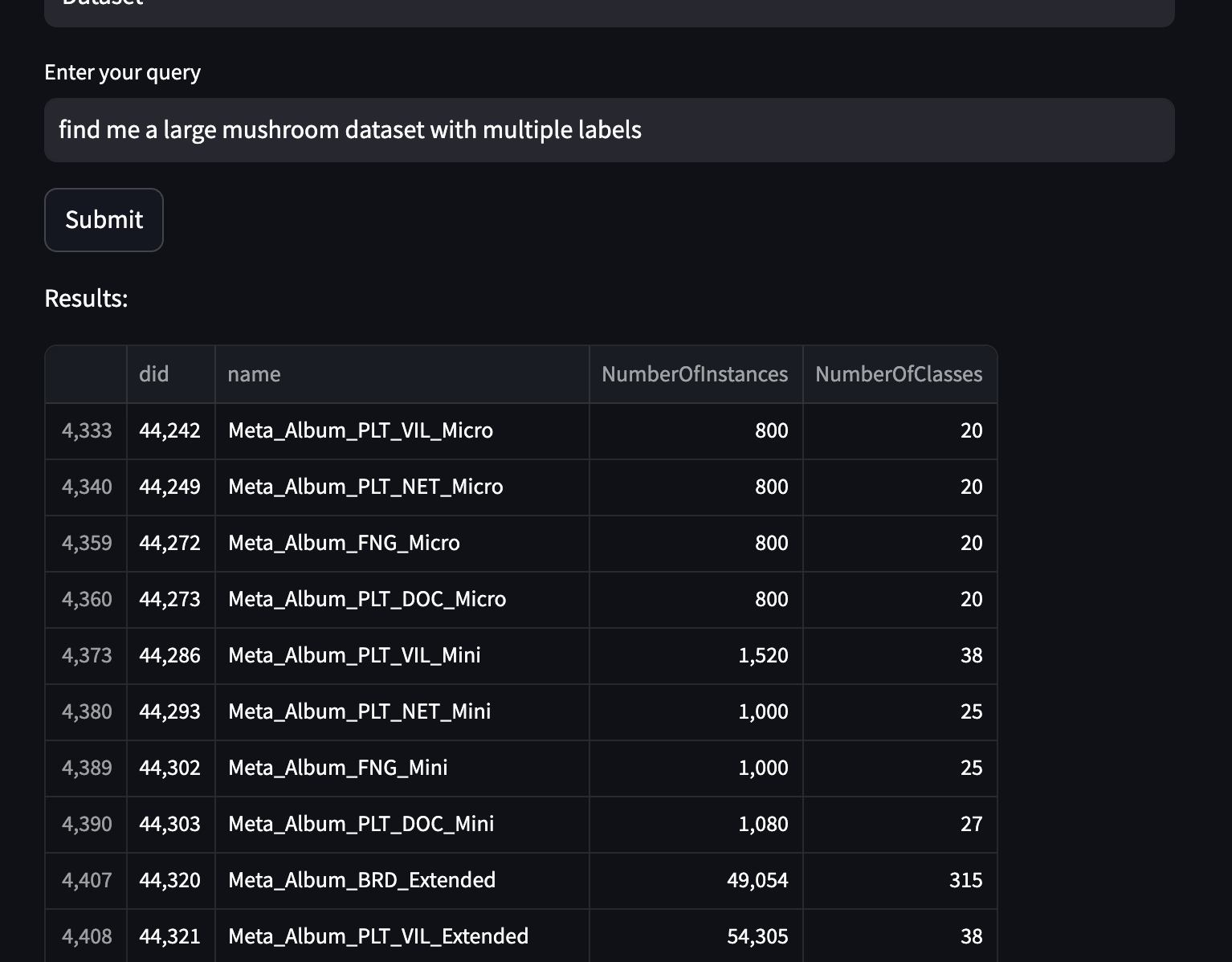
We all are lazy sometimes and don't want to use the interface sometimes. Or just want to test out different parts of the API without any hassle. To that end, you can either test out the individual components like so:
This is the server that runs an Ollama server (This is basically an optimized version of a local LLM. It does not do anything of itself but runs as a background service so you can use the LLM).
You can start it by running cd ollama && ./get_ollama.sh &