October 2019
Twice a year the OpenML community meets for a workshop/hackathon/unconference. We improve the platform, discuss and learn for 5 days. If that sounds interesting to you, get in touch or follow updates on meet.openml.org.
This time the workshop took place at Dagstuhl, a great place for Seminars.


We had several breakouts where workshop attendees can join to learn, discuss and progress OpenML. In the following we discuss some of the topics we touched.
Science projects
Brainstorm on scientific projects to do with OpenML. Prioritize impactful, well-defined research ideas. We came up with quite a long list of very promising research questions that should actually be quite easy to answer based on OpenML. Many of these are along the lines of empirically providing evidence to verify or bust commonly-held beliefs in the community. Frank would gladly hire a strong postdoc (or quite independent PhD student) and maybe a research engineer, to work on these scientific questions under the umbrella of “evidence-based machine learning with OpenML”.
Benchmarking using OpenML
Define guidelines on how to define world-class benchmarks and how to run them.
Diverse datasets
New and more diverse datasets.
Dataset quality
How to measure data quality and how to improve the quality of datasets on OpenML.
OpenML use cases for novices
Shortlist common use cases and start writing accessible blog posts for novice users. If you are a OpenML newbie we need your help with this topic.
The output of this breakout will be at least one blog post. Keep an eye out for them here :)
Running a competition using OpenML
We assessed the current issues with running in-class competitions for teaching purposes using OpenML (biggest one: easy use for non-developers) and brainstormed on a new competition format with related competitions, one for each component of a solution, such as HPO, creating good meta-features, creating a good search space, etc.
Planning future workshops
Decide on location and timing for the next couple of workshops. The next OpenML workshop will be in Spring (week of March 30th or week of April 14th) close to Munich. For updates check http://meet.openml.org. The workshop will be cohosted with some other Open Source Machine Learning projects.
Furthermore a workshop in Austin is being planned for next summer and a datathon is in planning. We are planning to organize dev sprints at various PyCons next year.
New frontend
Feedback session on new frontend, Additional visualization for datasets
Future of client APIs
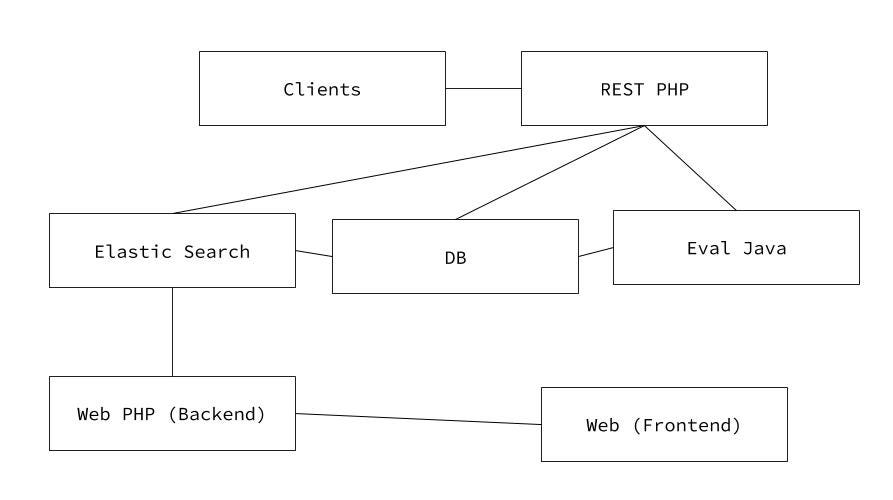
Currently, a lot of resources are bound developing different client APIs, such as the Python API, R API and Java API. We discussed how we can better share work and code between the different APIs and the server. For now we are working on automatically generating the Swagger API documentation from the PHP function documentation, which in turn will allow us to generate (documented) parts of the APIs, reduce the need for maintenance and will help to spread updates on the API faster.
Flow 2.0 design
Current flow design used in OpenML was inspired by Weka, but through time many limitations have been identified, primarily that existing flow does not allow duplicate use of same component and that it cannot express DAG-based ML programs. We started working on a new specification building on insights from mlr3 and d3m projects, centered around DAG representation. Current plan is to prepare a draft specification and implement prototype converters between other systems and this new specification. Once we do that we will re-evaluate the amount of work it took to build those prototypes and how well the specification satisfied those other systems.
Random Bot
The LRZ in Munich provided us with CPU time during the SuperMUC-NG supercomputer test phase, which we used to perform experiments of popular machine learning algorithms with random hyperparameter configurations. This resulted in millions of data points on more than a hundred datasets that we will analyse and publish. The data can be used to learn about typical behaviour of different learners across different datasets, and to construct surrogate models for tuning algorithm benchmarks.
AutoML Benchmark (Janek)
A study was created containing 76 binary and multiclass tasks of reasonable difficulty.
These can be used as a more difficult version of OpenML-100 or in amlb a platform for reproducible benchmarking of AutoML systems.
R API
Short session on how the R api will (need to) change. The main issue discussed was that the OpenML R package runs with mlr and breaks when the new package (mlr3) is loaded. We will update the current OpenML R package to work with mlr3. At the same time we are thinking about a vision for a rewrite of the OpenML R package.
Python API
We made a lot of improvements to the Python API over the week, with over 20 PRs merged! We’ve added more examples on how to use the package, fixed bugs, improved documentation and refactored code. In the coming days we’re going to make all these improvements available in a new PyPI release. For those looking for a higher level overview of the package, we will publish a paper next week which highlights use-cases, its software design, and project structure.
Benchmarking paper
We are working on a comprehensive paper using sklearn, mlr and WEKA, which should demonstrate how OpenML can be used for proper benchmarking and analysis.
Guidelines / Overfitting / Comparable Metalearning
There are plans for writing a guidelines and pitfalls paper on benchmarking, meta-overfitting and statistical analysis of results on OpenML.
Data Formats
Currently OpenML supports only tabular data in ARFF data format. This is very limiting for many ML tasks. We discussed and explored other data formats we could use as the future next data format. We will post a separate blog post about our process and insights.
Funding
OpenML is looking for funding (developers). New ideas on obtaining funding are very welcome. We discussed some ideas: American funding (we need a collaboration partner); ALICE / CLAIRE; Companies. We are a foundation now, which might make it easier.
Some of the PIs (in particular Bernd Bischl, Frank Hutter and Dawn Song) in the project offer positions with a mix of ML research and development. Contact them if you are interested!

We had some talks at the workshop as well:
Mitar Milutinovic: A short introduction to Data Driven Discovery (D3M)
Yiwen Zhu and Markus Weimer: Large-scale analysis of Jupyter notebooks
Martin Binder, Michel Lang, Florian Pfisterer, Bernd Bischl: Pipelining with mlr3
… and lots of fun…

Wanna join the OpenML community? Get in touch!